This walktrough is outdated. Please see the posts for the 2024 updated version:
Updated Version
As VMware states on their documentation for the NSX Application Platform either Tanzu Kubernetes Grid (TKG) or any other Upstream Kubernetes Platform (meaning the Open-Source Kubernetes / K8S Distribution) is supported for NSX-Application-Platform (Napp) Deployment. During this series, I will try to give an of the steps and how I’ve managed to get the deployment running.
In this post, I will go through installing Rocky Linux and building the Kubernetes Cluster with a working Container Network and Container Storage Infrastructure (CNI & CSI).
In a separate post, I will describe setting up the Napp and a private Harbor repository, as I’ve found VMware’s public repository to be quite slow and also not delivering needed images at all (Image-Pull-Errors).
Please note that the instructions given in this blog post are provided as is and may only be working at the time of writing. I’m also in no way a Kubernetes “expert” so please take everything written here with a grain of salt and do research on your own.
Licensing & Resource Requirements
Depending on your license you can choose between the standard and the advanced form factor of the Napp-Deployment. While the standard form factor comes with the Metrics, Malware Prevention, and Network Detection and Response features, Advanced adds the NSX Intelligence feature set (NSX Intelligence- Distributed Security and Analytics Engine | VMware).
Do note that the Malware, Network Detection and Intelligence features may not be included in your license. For Intelligence, you need at least an NSX Advanced license, while the security features may need Add-On licenses.
The form factor also determines your deployment size. At least you will need one Kubernetes leader for the control plane and three followers as worker nodes. In my deployment, the control plane will be sized reasonably small at 2 vCPUs, 8GB RAM, and 150GB of storage, while the workers will get 4 vCPUs, 16GB RAM, and a shared total of 200GB NFS storage. For the advanced form factor you will at least need 3 worker nodes with 16 vCPUs and 64GB RAM with a total of 1TB of shared NFS storage.
Installing Rocky Linux 9.1
For those who might not know, Rocky Linux is the inofficial successor to CentOS 8 and a derivative of Red Hat Enterprise Linux, which suits perfectly for enterprise needs. You may find many tutorials on Ubuntu, which is also perfectly valid – for most deployments, it will come down to personal preference.
You can download Rocky Linux at their official site here: Download Rocky | Rocky Linux
Make sure to choose the “Minimal” image as we don’t want the overhead of a GUI.
Create 4 VMs in vCenter with at least the following requirements:
- Leader / Control Plane
- 2 vCPU
- 4GB RAM
- 100GB Storage
- 3 Worker Nodes
- 4 vCPU
- 8GB RAM
- 100GB Storage
The machines will only need 1 network adapter in their management network.
Mount the ISO and start the Rocky Installer. The workflow then is quite easy and as you’re probably a VMware administrator you should be more than able to complete the process. Just install the OS to your liking.
When the OS is booted up, create SSH keys and import them to the hosts.
OS Preparation – Tasks on all Hosts
As the first step, update the system and install some common packages that will be needed in the guide.
sudo yum update -y
sudo yum install nano git tar wget nfs-utils -yThen disable Linux swap as this is needed for Kubernetes and set SELinux into permissive mode so that host operations done by the Kubernetes services will succeed.
sudo swapoff -a
sudo sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
sudo setenforce 0
sudo sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/configYou will also need to correctly set the time service as the Napp deployment will generate certificates that need correct timestamps. You may also configure your internal NTP server beforehand, in my deployment I will just use the default Rocky-Linux NTP server.
sudo timedatectl set-ntp on
sudo systemctl restart chronyd
sudo timedatectlNext is firewall configuration. You will need these Ports for intra-cluster communication.
sudo firewall-cmd --permanent --add-port=6443/tcp
sudo firewall-cmd --permanent --add-port=2379-2380/tcp
sudo firewall-cmd --permanent --add-port=10250/tcp
sudo firewall-cmd --permanent --add-port=10251/tcp
sudo firewall-cmd --permanent --add-port=10252/tcp
sudo firewall-cmd --permanent --add-port=30000-32767/tcp
sudo firewall-cmd --reload
Also, Antrea will need some ports. You can see which ones are required for your deployment on their official documentation.
sudo firewall-cmd --permanent --add-port=443/tcp
sudo firewall-cmd --permanent --add-port=7471/tcp
sudo firewall-cmd --permanent --add-port=4789/udp
sudo firewall-cmd --permanent --add-port=6081/udp
sudo firewall-cmd --permanent --add-port=10349-10350/tcp
sudo firewall-cmd --reloadAs the last step in firewall configuration, MetalLB will also need a communication port:
sudo firewall-cmd --permanent --add-port=7946/tcp
sudo firewall-cmd --permanent --add-port=7946/udp
sudo firewall-cmd --reload
We will use containerd as our containering solution. You need to enable the overlay and br_netfilter kernel extensions, as well as to enable IP forwarding on iptables:
sudo cat > /etc/modules-load.d/containerd.conf <<EOF
overlay
br_netfilter
EOF
sudo cat > /etc/sysctl.d/99-kubernetes-cri.conf <<EOF
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
net.bridge.bridge-nf-call-ip6tables = 1
EOF
sudo sysctl --system
sudo modprobe overlay
sudo modprobe br_netfilterNow we can add the containerd repo and install the required packages:
sudo dnf config-manager --add-repo=https://download.docker.com/linux/centos/docker-ce.repo
sudo dnf install -y containerd.ioAfter that, we can configure containerd. As Kubernetes in the 1.23 version is not able to use the cgroupv2 implemented in Rocky Linux 9, we need to tell containerd to use the default systemd. To do that, we will first create a copy of the default config file and edit it afterward:
sudo mkdir -p /etc/containerd
sudo containerd config default | sudo tee /etc/containerd/config.toml
sudo nano /etc/containerd/config.tomlIn the file, you will set the following parameter to “true”. Be sure to change the value under the correct section.
#[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc]
# ...
# [plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
# SystemdCgroup = true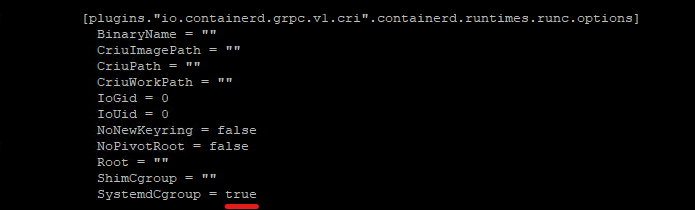
Save the file – now we can start the containerd daemon.
sudo systemctl enable containerd --nowNow we continue with the Kubernetes package deployment. For that, we will need to add the repo and install the packages in the specific version the current Napp-Package supports. At the time of writing, 1.20 through 1.24 is supported – I will use version 1.23. After the installation, we can enable the Kubelet daemon.
sudo cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-\$basearch
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
exclude=kubelet kubeadm kubectl
EOF
sudo dnf install -y kubelet-1.23.0-0 kubeadm-1.23.0-0 kubectl-1.23.0-0 --disableexcludes=kubernetes
sudo systemctl enable kubelet --nowThis concludes our OS preparation. Be sure to complete these steps on all nodes of the Kubernetes cluster.
Kubernetes Cluster initialization / Tasks on Control Plane host
The next step is to initialize the Kubernetes Control Plane. You will only need to do this and the following tasks on the leader node/control plane. This is done by the command:
sudo kubeadm init --pod-network-cidr 10.20.0.0/16 --kubernetes-version 1.23.0We give the command the parameters to use the network 10.20.0.0/16 as the pod network. You can choose any network to your liking, as long as it’s big enough to accommodate all your hosts and pods. We also tell the kubeadm command to use Kubernetes version 1.23.0.
Kubeadm will then initiate a preflight-check of the parameters and the local system. Watch out for any errors or warning there – with the steps described here, my deployment was able to pass this check without any issues.
After that, the installer downloads the needed images to deploy the cluster and performs certificate signing steps. By default, a CA is created which creates self-signed certificates. If needed, you can change this behavior according to the official Kubernetes documentation.
Now you will need to add the kubeconfig file to your bash profile so that the kubectl command will be able to connect to the kubelet daemon. Otherwise, kubectl will not work. I also added the Kubeconfig to a system-wide variable so that other tools can access it easily.
sudo echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> /etc/profile.d/k8s.sh
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config
At the end of the output, there is also a block telling you the command with which you can join other nodes to the cluster. Be sure to write it down for now. I found it to be more reliable to join the other nodes once the CNI is installed in the next step.
You can always get the join command afterwards by running this on the control plane:
kubeadm token create --print-join-commandInstall a Container Networking Plugin
By default, the Kubernetes cluster is able to deploy pods, but these pods will not be able to communicate with each other.
There are popular plugins like Flannel, Weave, or Calico – but I will use Antrea in its Open-Source version as it’s developed by VMware, runs stable even with the simplest default configuration, and is very simple to set up.
You can just apply the deployment file directly in the latest version:
kubectl apply -f https://raw.githubusercontent.com/vmware-tanzu/antrea/master/build/yamls/antrea.ymlNow, join the follower nodes with the previously written down join command.
Quality-of-Life Tools
Kubernetes commands can get quite long – there are also very little “overview” options. To mend these problems let’s install some tools which will ease the usage of the cluster.
First, install K9S – this is a simple binary that uses the Kubeconfig-file and provides a Text-UI, where you can describe pods, read their logs, and much more. This little snippet will add K9S to your binaries.
mkdir ~/k9s
cd ~/k9s
wget https://github.com/derailed/k9s/releases/download/v0.27.3/k9s_Linux_amd64.tar.gz
tar -xzf k9s_Linux_amd64.tar.gz
mv ./k9s /usr/local/bin/k9s
cd ~
rm -R -f ~/k9s
For Kubernetes deployments, Helm is also very useful as you can get a “single-click” approach to deployments. You can get full instructions on their official site – the easiest way to install Helm however is via the command:
curl https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 | bashMetalLB
For the Napp-Deployment we will need a Load Balancer which hands out “public” IPs to the pods. What I found out to be working is MetalLB in a version that was roughly up-to-date when Kubernetes 1.23 was the newest version.
You can deploy MetalLB directly via:
kubectl apply -f https://raw.githubusercontent.com/metallb/metallb/v0.10.3/manifests/namespace.yaml
kubectl apply -f https://raw.githubusercontent.com/metallb/metallb/v0.10.3/manifests/metallb.yamlWhen the pods are running (check via “kubectl get pods -n metallb-system”), you can add a Configmap to the namespace. Be sure to set your IP range in the following snippet – you will need at least 5 addresses for the Napp:
cat > metallb-config.yaml <<EOF
apiVersion: v1
kind: ConfigMap
metadata:
namespace: metallb-system
name: config
data:
config: |
address-pools:
- name: default
protocol: layer2
addresses:
- ###STARTIP###-###ENDIP###
EOF
kubectl apply -f metallb-config.yamlContainer Storage Infrastructure
The deployed Pods / Containers will also need network-backed storage to save their data and configuration. For that purpose, our Kubernetes cluster will need a CSI plugin, which hands out a storage class to use. In my case, I settled on the plugin “nfs-subdir-external-provisioner”, as NFS is easy to use and my underlying storage system already supports NFS exports.
The plugin is easy to use and you only need this command to deploy the plugin via helm – be sure to replace the values with your data. You need to make sure that the NFS export works with NFSv4 and is sized according to the Napp form factor you will use. You can check any other details on the plugin’s page on GitHub: GitHub – kubernetes-sigs/nfs-subdir-external-provisioner: Dynamic sub-dir volume provisioner on a remote NFS server.
helm repo add nfs-subdir-external-provisioner https://kubernetes-sigs.github.io/nfs-subdir-external-provisioner/
helm install nfs-subdir-external-provisioner nfs-subdir-external-provisioner/nfs-subdir-external-provisioner \
--set nfs.server=###IP-or-FQDN### \
--set nfs.path=###NFS-Share-Path###Testing
To test the cluster, you can deploy these two Kubernetes-Deployments.
First, for the Load Balancer and Intra-Cluster-Communication over the CNI, deploy the Yelb 3-Tier-App:
kubectl create ns yelb
kubectl -n yelb apply -f https://raw.githubusercontent.com/lamw/yelb/master/deployments/platformdeployment/Kubernetes/yaml/yelb-k8s-loadbalancer.yamlThis will create the new Kubernetes-Namespace “yelb” and four new pods in there. Once they are running (check with “kubectl get pods -n yelb”), you can check if an external IP was assigned to the UI-Pod with “kubectl get service -n yelb”. This proves, that MetalLB is providing IP addresses to the Pods.
You should be able to reach the external IP address provided and see a website where you (and your colleagues 😉) can vote for today’s lunch. If so, the CNI is also working as intended.
You can simply delete the app afterward via:
kubectl delete namespace yelbFor the Container Storage Infrastructure, the Testpod provided by the nfs-subdir-external-provisioner repo works well:
kubectl create -f https://raw.githubusercontent.com/kubernetes-sigs/nfs-subdir-external-provisioner/master/deploy/test-claim.yaml -f https://raw.githubusercontent.com/kubernetes-sigs/nfs-subdir-external-provisioner/master/deploy/test-pod.yamlThis will deploy the “test-pod” and a “test-claim” provisioned-volume-claim into your default namespace. You can then use “kubectl describe pvc test-claim” to see an overview of the claim. It should conclude with a message like: “Successfully provisioned volume pvc-XXXXXXXXXXXXXX” in the events section.

Otherwise, you will get an error message describing the failure reason.
You can delete this test with the command:
kubectl delete -f https://raw.githubusercontent.com/kubernetes-sigs/nfs-subdir-external-provisioner/master/deploy/test-claim.yaml -f https://raw.githubusercontent.com/kubernetes-sigs/nfs-subdir-external-provisioner/master/deploy/test-pod.yamlThat’s it for now. You should now have a fully functional Upstream Kubernetes / K8S cluster just waiting for the NSX application platform. Check out Part 2 to deploy Harbor and the actual NSX Application Platform: Deploy NSX Application Platform on Upstream Kubernetes (Part 2, Harbor Registry, Napp Deployment)